Thành Viên Nhóm
1. Tổng Quan Cloud Computing (Lab 1)
I. Kiến Thức Cơ Bản
Cloud Computing: Việc cung cấp các dịch vụ CNTT (server, lưu trữ, phần mềm) qua Internet mà không cần sở hữu hạ tầng vật lý.
IaaS (Infrastructure)
Thuê hạ tầng thô (OS, CPU, Ổ cứng). Người dùng tự quản trị toàn bộ hệ điều hành.
PaaS (Platform)
Thuê nền tảng để triển khai code. Không cần lo về OS hay cập nhật bản vá.
SaaS (Software)
Sử dụng phần mềm hoàn chỉnh trên web. Không cần cài đặt hay lập trình.
Cloudflare Pages
Là dịch vụ PaaS giúp biến mã nguồn (HTML/JS) thành Website truy cập toàn cầu.
CDN (Content Delivery Network)
- Tăng tốc: Cache dữ liệu tại server gần người dùng nhất.
- Bảo mật: Ẩn IP gốc của máy chủ, hứng chịu tấn công DDoS.
II. Rủi Ro & Giải Pháp (Web Tĩnh)
Dù hạ tầng Cloud an toàn, rủi ro thường đến từ cấu hình sai của người dùng (Shared Responsibility).
| Rủi ro thường gặp | Giải pháp khắc phục |
|---|---|
|
Lộ thông tin nhạy cảm
Lưu cứng (Hard-code) API Key, Mật khẩu trong file HTML/JS công khai.
|
Kiểm soát mã nguồn
Rà soát code trước khi đẩy lên Git. Sử dụng biến môi trường (Environment Variables).
|
|
XSS & Clickjacking
Trình duyệt thực thi mã độc do thiếu hướng dẫn bảo mật.
|
Security Headers
Cấu hình HSTS, CSP, X-Frame-Options (File _headers).
|
|
Truy cập trái phép
Người lạ truy cập vào trang nội bộ/staging.
|
Cloudflare Access
Bật xác thực qua Email cho các trang nội bộ (Zero Trust).
|
2. Thiết Lập Zero Trust (Lab 2)
Yêu cầu 1: Authentication vs Authorization

[HÌNH 1: SỰ KHÁC BIỆT AUTHENTICATION & AUTHORIZATION]
+ Authentication: Là quá trình xác thực người dùng sẽ là “ai” trong hệ thống.
+ Authorization: Là quá trình xác thực những loại tài nguyên nào sẽ được cung cấp.
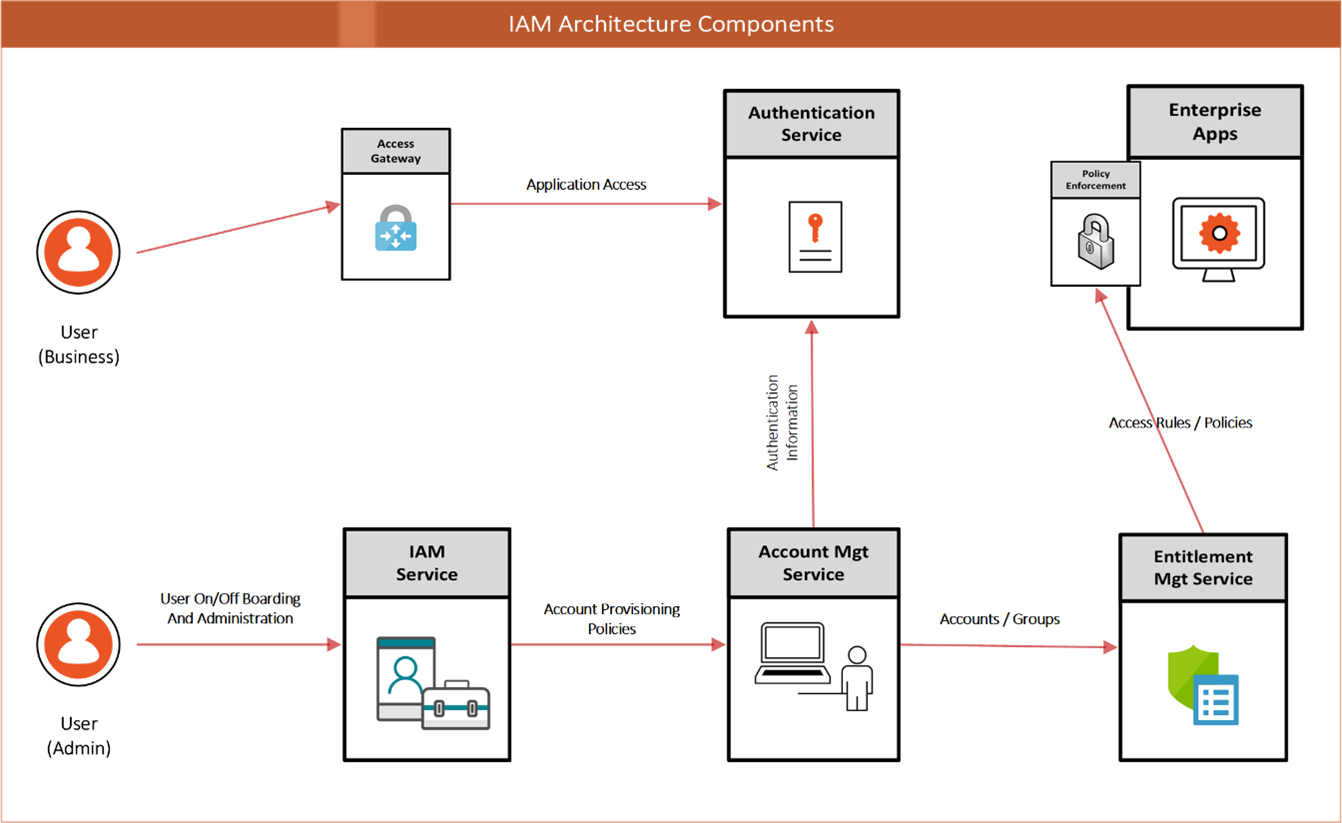
[HÌNH 2: MÔ HÌNH IAM]
IAM: Xác minh danh tính và kiểm soát tài nguyên người dùng có thể truy cập.
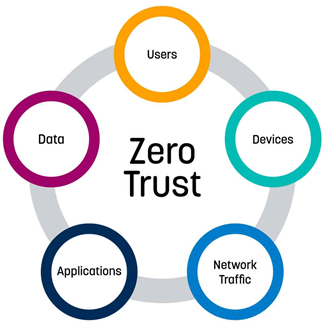
[HÌNH 3: ZERO TRUST MODEL]
Zero Trust: Mô hình giả định mọi request đều có thể là thù địch, cần xác thực nghiêm ngặt.
Yêu cầu 2: Quy trình & Mô hình
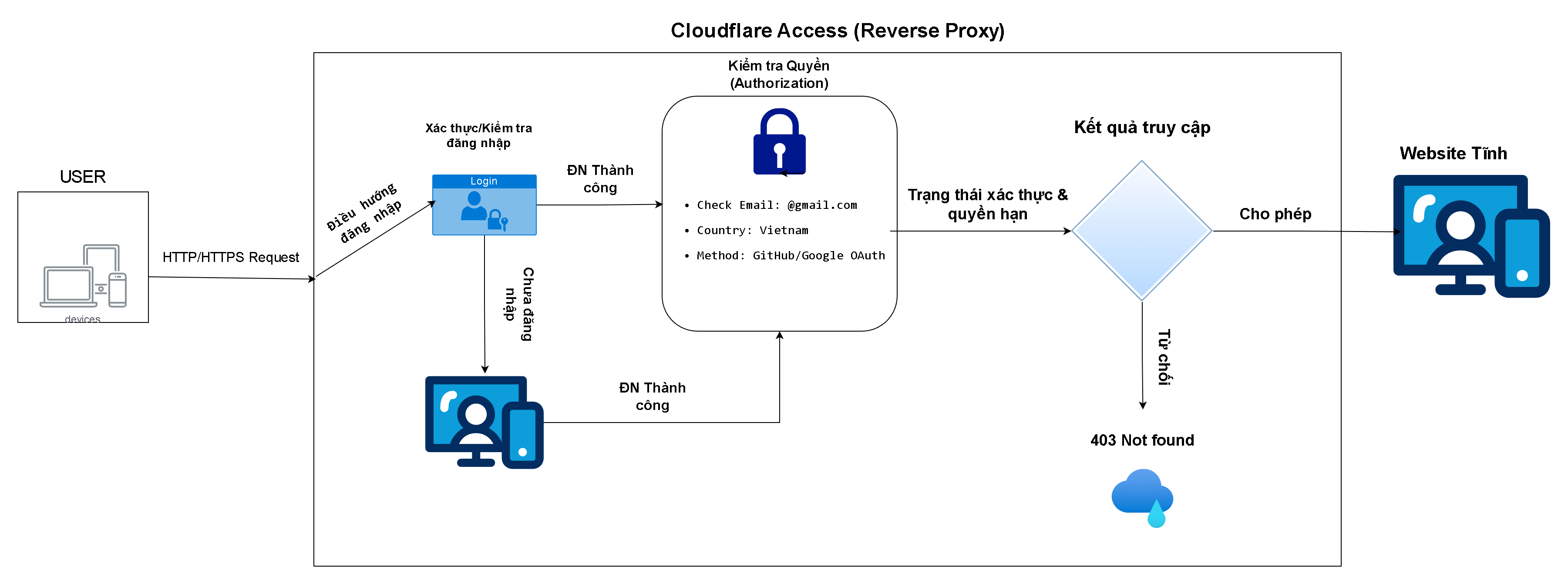
[HÌNH 4: THIẾT KẾ MÔ HÌNH KIỂM SOÁT TRUY CẬP]
Các thành phần tham gia: Người dùng (User), Lớp kiểm soát (Cloudflare Access), Khối xác thực (Authentication), Khối kiểm tra quyền (Authorization), Website tĩnh (Cloudflare Pages).
Thứ tự xử lý: Trình duyệt gửi request -> Cloudflare chặn lại -> Yêu cầu đăng nhập GitHub -> Kiểm tra Email có trong danh sách cho phép không -> Cho phép hoặc Từ chối.
Cấu Hình Bảo Mật Và Kiểm Thử
1. Đạt loại A về bảo mật (Security Headers)
Để đảm bảo an toàn thông tin, dự án đã cấu hình tệp _headers tại thư mục gốc của website với các chỉ thị quan trọng:
Chặn các nguồn script lạ, chỉ cho phép load dữ liệu từ các nguồn tin cậy.
Ép buộc trình duyệt luôn sử dụng kết nối mã hóa HTTPS.
Ngăn chặn tấn công Clickjacking bằng cách không cho phép website hiển thị trong iframe.
Ngăn chặn trình duyệt đoán sai định dạng tệp (MIME sniffing).
Kết quả cấu hình:
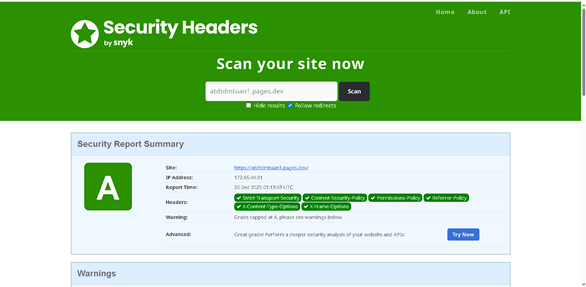
[HÌNH 5: KẾT QUẢ KIỂM TRA SECURITY HEADERS ĐẠT LOẠI A]
Chi tiết tệp _headers:
Yêu cầu 3: So sánh mô hình bảo mật
| Mô hình 1: Bảo mật mạng truyền thống | Mô hình 2: Zero Trust trong môi trường Cloud |
|---|---|
| "Trust but Verify". Tập trung bảo vệ bờ tường bao quanh hệ thống. | "Never Trust, Always Verify". Tập trung bảo vệ dữ liệu/ứng dụng cụ thể. |
| Tin cậy nội bộ (Implicit Trust): Mặc định an toàn khi ở trong mạng nội bộ. | Không có vùng an toàn: Mọi request đều bị coi là thù địch cho đến khi xác thực xong. |
| Dựa trên địa chỉ IP & Vị trí mạng. | Dựa trên Định danh & Ngữ cảnh (Identity, Device Health). |
| Tập trung kiểm soát việc ra vào mạng lưới. | Kiểm soát chặt chẽ ngay cả khi đã truy cập vào bên trong. |
3. Bảo Mật Ứng Dụng Web (Lab 3)
I. Tổng Quan Về Bảo Mật Web & OWASP
1. Phân biệt HTTP, TLS và HTTPS
Giao thức truyền tải văn bản thuần (plaintext). Dữ liệu không được mã hóa, ai bắt được gói tin cũng đọc được nội dung.
(Transport Layer Security) Là lớp vỏ bảo vệ, sử dụng thuật toán mã hóa để biến dữ liệu thành các ký tự vô nghĩa.
HTTP chạy trên nền TLS. Đảm bảo 3 yếu tố: Mã hóa (Giấu tin), Toàn vẹn (Không bị sửa), Xác thực (Đúng server).
2. OWASP Top 10 là gì?
OWASP Top 10 là tài liệu nhận thức chuẩn mực về 10 rủi ro bảo mật ứng dụng web quan trọng nhất. Đây là sự đồng thuận của các chuyên gia bảo mật toàn cầu.
Mục tiêu: Giúp các tổ chức, lập trình viên nhận diện, ưu tiên và xử lý lỗ hổng để giảm thiểu rủi ro bị tấn công.
II. Phân Tích Các Lỗ Hổng (OWASP Juice Shop)
Phần này phân tích chi tiết nguyên nhân, dấu hiệu và cách phòng chống cho từng lỗ hổng đã thực hành.
1. Injection (SQL Injection)
Cơ chế: Kẻ tấn công chèn các câu lệnh SQL độc hại vào ô nhập liệu (Input) để thao túng cơ sở dữ liệu phía sau.
Kịch bản thực hành: Đăng nhập vào tài khoản Admin mà không cần mật khẩu.
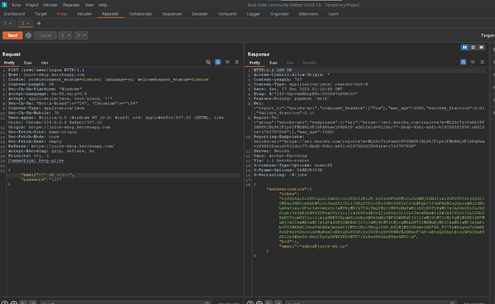
Hậu quả: Mất dữ liệu, lộ thông tin khách hàng, chiếm quyền kiểm soát hệ thống.
Khắc phục: Sử dụng Prepared Statements (Câu lệnh tham số hóa) để tách biệt dữ liệu và câu lệnh.
2. Broken Access Control (Lỗi phân quyền)
Cơ chế: Ứng dụng không kiểm tra kỹ quyền hạn của người dùng, cho phép họ truy cập vào dữ liệu của người khác hoặc trang quản trị.
Kịch bản thực hành: Xem giỏ hàng của người dùng khác hoặc truy cập trang `/administration`.
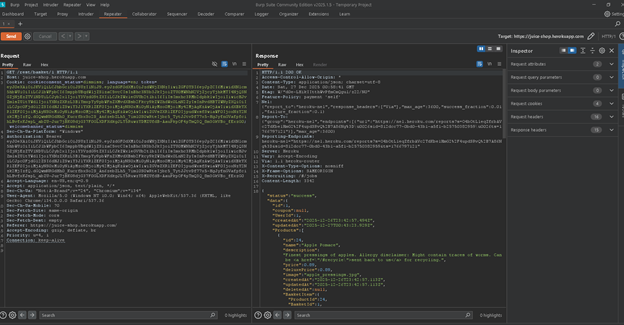
Khắc phục: Thực hiện kiểm tra quyền sở hữu (Ownership Check) ở phía Server cho mọi request (Mô hình: if UserID != ResourceOwner then Deny).
3. Cryptographic Failures (Lỗi mã hóa)
✅ Dấu hiệu nhận biết:
- Lộ mật khẩu yếu / Hash không an toàn.
- Token/JWT cấu hình kém.
- Dữ liệu nhạy cảm bị lộ do mã hóa yếu.
Kịch bản thực hành: Bắt Request, lấy Token và Decode để xem dữ liệu bên trong.
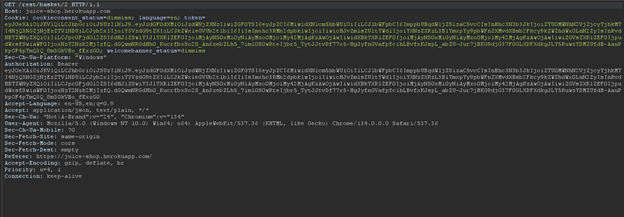
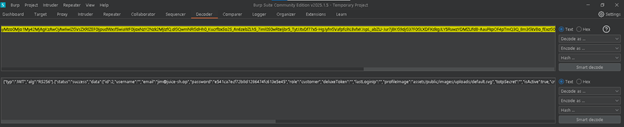
Kết quả phân tích (Decode):
- ❌ Token chứa password hash: Nguy cơ bị Crack mật khẩu.
- ❌ Token chứa thông tin dư thừa: Lộ email, role, ID.
- ❌ Mã hóa yếu: Dữ liệu chỉ là Base64, ai cũng đọc được.
III. Triển Khai Docker & Sửa Lỗi (Mô phỏng)
1. Triển khai Juice Shop
Sử dụng Docker để tạo môi trường lab cô lập:
Ứng dụng chạy tại: http://localhost:3000
2. Mô phỏng sửa Code (SQLi)
IV. Đánh Giá Rủi Ro Đặc Thù Trên Cloud
| Khía cạnh | Chi tiết |
|---|---|
| Denial of Wallet | Tấn công vào "ví tiền". Hacker chiếm server để đào tiền ảo hoặc gửi spam, khiến hóa đơn Cloud tăng vọt (hàng nghìn USD) chỉ sau một đêm. |
| Shared Responsibility | Mô hình "Trách nhiệm chia sẻ". Cloud Provider bảo vệ hạ tầng (Network, Hardware), nhưng Khách hàng phải chịu trách nhiệm cấu hình (OS, App, Data). |
| Giải pháp (Defense in Depth) |
|
4. Monitoring & Logging (Lab 4)
I. Tổng Quan: Monitoring, Logging & Visibility
1. Monitoring (Giám sát)
(Tham khảo: Cloudflare - What is Monitoring)
Khái niệm: Monitoring là quá trình quan sát liên tục sự hiện diện, hiệu suất và sức khỏe của các hệ thống, máy chủ, ứng dụng hoặc cơ sở hạ tầng mạng. Nó liên quan đến việc thu thập các số liệu (metrics) theo thời gian thực để đảm bảo hệ thống hoạt động như mong đợi.
- Nội dung thu thập: Các chỉ số định lượng (CPU, RAM, băng thông, latency, tỷ lệ lỗi) và tính sẵn sàng (Availability/Uptime).
- Cơ chế: Real-time alerting (Gửi cảnh báo ngay lập tức khi chỉ số vượt ngưỡng).
- Mục đích: Phát hiện sớm sự cố, đảm bảo chất lượng dịch vụ (QoS) và quy hoạch tài nguyên.
2. Logging (Ghi nhật ký)
Khái niệm: Logging là quá trình ghi lại các sự kiện rời rạc xảy ra trong hệ thống. Mỗi log entry là một bản ghi chi tiết về một sự kiện cụ thể tại một thời điểm nhất định.
- Nội dung log: Timestamp (Thời gian), Source (Nguồn), Event (Sự kiện - Lỗi, đăng nhập, transaction), Context (User ID, IP).
- Mục đích: Truy vết sự cố (Troubleshooting), phân tích nguyên nhân gốc rễ (Root Cause Analysis), và Audit (kiểm toán bảo mật).
3. Security Visibility (Khả năng quan sát an ninh)
Khái niệm: Là khả năng nhìn thấy và hiểu được những gì đang diễn ra trong toàn bộ hạ tầng IT. Nó là bức tranh tổng thể được ghép lại từ Monitoring và Logging.
Mục đích: Trả lời câu hỏi "Hệ thống của tôi có thực sự an toàn không?" và phát hiện các mối đe dọa tiềm ẩn (Shadow IT, hành vi bất thường).
II. So Sánh & Vấn Đề Chuyên Sâu
1. Phân biệt Monitoring và Logging
| Tiêu chí | Monitoring (Giám sát) | Logging (Ghi nhật ký) |
|---|---|---|
| Bản chất | Nhìn vào tổng thể và xu hướng (Trends). | Nhìn vào chi tiết từng sự kiện (Events). |
| Câu hỏi | "Hệ thống có khỏe không?" (Health). | "Tại sao nó bị bệnh?" (Debug/Forensics). |
| Dữ liệu | Metrics (Số liệu: 80% CPU, 200ms latency). | Text/JSON (File ghi: "Error at line 40..."). |
| Thời gian | Real-time (Thời gian thực). | Lịch sử (Lưu trữ để tra cứu sau). |
2. Các vấn đề chuyên sâu trên Cloud
- Tính nhất thời (Ephemeral): Server có thể sinh ra và mất đi trong vài phút. Nếu không log kịp, dữ liệu sẽ mất vĩnh viễn.
- Mô hình chia sẻ trách nhiệm: Bạn không kiểm soát phần cứng, nên Log là "bằng chứng" duy nhất để biết lỗi do mình hay do nhà cung cấp (AWS/Azure).
- Lỗi Logic ứng dụng: Cloud biết CPU thấp (tốt), nhưng không biết ứng dụng đang tính sai tiền cho khách.
- Trải nghiệm người dùng (Real User Experience): Server báo "Xanh", nhưng khách hàng mạng yếu vẫn thấy web chậm.
- Nội dung RAM: Cloud Provider không can thiệp vào dữ liệu trong Memory của khách hàng.
III. Quy Trình Ứng Phó Sự Cố (Incident Response)
1. Giai đoạn Phát hiện (Detect) - Vai trò của Monitoring
Ví dụ: Monitoring đóng vai trò như "Chuông báo trộm".
Chỉ số quan trọng: Giúp giảm MTTD (Mean Time To Detect - Thời gian trung bình để phát hiện).
Nó cho biết KHI NÀO sự cố bắt đầu xảy ra.
2. Giai đoạn Phản ứng & Khắc phục - Vai trò của Logging
Ví dụ: Logging đóng vai trò như "Camera an ninh".
Chỉ số quan trọng: Giúp giảm MTTR (Mean Time To Resolve - Thời gian trung bình để khắc phục).
Nó cung cấp dữ liệu để vá lỗi, chặn IP và khôi phục.
3. Tác động của thời gian phát hiện (Latency of Detection)
- Hậu quả: Gián đoạn ngắn, mất ít dữ liệu.
- Xử lý: Chặn IP, reset session. Uy tín ít bị ảnh hưởng.
- Hậu quả: Hacker đã leo thang đặc quyền, cài Backdoor, trích xuất toàn bộ dữ liệu.
- Xử lý: Tốn kém, mất uy tín nghiêm trọng.
5. Ứng Phó Sự Cố & Tổng Hợp (Lab 5)
1. Kiến Thức Cơ Bản Về Incident Response (IR)
1.1. Incident Response là gì?
(Tham khảo: Cloudflare)
Incident Response (IR) – Ứng phó sự cố an toàn thông tin – là một quy trình có cấu trúc và có kế hoạch mà tổ chức sử dụng để chuẩn bị, phát hiện, phân tích, xử lý và phục hồi sau các sự cố an ninh mạng như tấn công mạng, lộ dữ liệu hoặc vi phạm bảo mật.
Mục tiêu của Incident Response không chỉ là khắc phục sự cố đã xảy ra mà còn:
- Giảm thiểu thiệt hại về dữ liệu, tài chính và uy tín.
- Rút ngắn thời gian gián đoạn dịch vụ.
- Giảm chi phí khắc phục hậu quả.
- Ngăn chặn sự cố tương tự tái diễn trong tương lai.
1.2. Chu trình Incident Response theo NIST
(Tham khảo: NIST SP 800-61). Theo tiêu chuẩn của NIST, chu trình Incident Response gồm 4 giai đoạn chính, diễn ra liên tục và có tính cải tiến:
1. Preparation (Chuẩn bị)
Bao gồm xây dựng chính sách an ninh, đào tạo nhân sự, triển khai công cụ giám sát, logging và chuẩn bị kịch bản ứng phó sự cố.
2. Detection & Analysis (Phát hiện & Phân tích)
Giám sát hệ thống để phát hiện các dấu hiệu bất thường, phân tích log và đánh giá mức độ nghiêm trọng của sự cố.
3. Containment, Eradication & Recovery
(Ngăn chặn, loại bỏ và phục hồi). Cô lập vùng bị ảnh hưởng, loại bỏ nguyên nhân gây sự cố và khôi phục hệ thống về trạng thái an toàn.
4. Post-Incident Activity (Hoạt động sau sự cố)
Đánh giá nguyên nhân gốc rễ (Root Cause Analysis), rút kinh nghiệm và cải tiến quy trình bảo mật.
2. Vai Trò IR Trong Cloud & Dấu Hiệu Nhận Biết
Vai trò đặc thù trong Cloud:
-
Shared Responsibility Model:
IR giúp xác định nhanh sự cố thuộc trách nhiệm của nhà cung cấp cloud (hạ tầng, mạng) hay của người dùng (ứng dụng, dữ liệu), từ đó phối hợp xử lý hiệu quả.
-
Tốc độ lan truyền cao:
Hệ thống cloud kết nối toàn cầu, sự cố có thể lan rộng rất nhanh nếu không phát hiện kịp.
-
Tính nhất thời (Ephemeral):
Máy chủ ảo có thể bị xóa nhanh chóng, IR đảm bảo thu thập log và chứng cứ số (forensics) kịp thời.
3. Dấu Hiệu (Indicators of Compromise - IoC):
- Lưu lượng mạng: Traffic tăng đột biến (nghi ngờ DDoS) hoặc dữ liệu lớn gửi ra IP lạ (rò rỉ dữ liệu).
- Hành vi tài khoản: Đăng nhập giờ lạ, vị trí lạ, leo thang đặc quyền trái phép.
- Hiệu năng hệ thống: CPU/RAM cao liên tục (nghi ngờ bị cài coin miner).
- Hệ thống và log: Log bị xóa đột ngột, xuất hiện file lạ, WAF cảnh báo liên tục.
4. Phân Loại Sự Cố An Toàn Thông Tin
Dựa trên các dấu hiệu phát hiện, sự cố có thể được phân loại như sau:
| Loại sự cố | Dấu hiệu & Chi tiết |
|---|---|
| 4.1. Lộ tài khoản (Compromised Account) | Tài khoản đăng nhập thành công nhưng thực hiện các hành động bất thường như xóa dữ liệu, tạo máy ảo trái phép hoặc thay đổi cấu hình bảo mật. |
| 4.2. Tấn công Brute-force | Log ghi nhận hàng nghìn yêu cầu đăng nhập thất bại (HTTP 401/403) từ cùng một IP hoặc dải IP trong thời gian ngắn. |
| 4.3. Khai thác lỗ hổng ứng dụng |
Log xuất hiện các payload bất thường như ' OR 1=1, ../etc/passwd, <script>...Liên hệ OWASP: Thường liên quan đến Injection, Broken Access Control hoặc Security Misconfiguration. |
5. Vai Trò Của Monitoring và Logging
Câu hỏi: Nếu không có monitoring và logging, sự cố có được phát hiện không? Vì sao?
Trả lời: Gần như không thể phát hiện sớm, hoặc chỉ phát hiện khi sự cố đã gây ra hậu quả nghiêm trọng.
Lý do:
- Không có log giống như vận hành hệ thống trong trạng thái “mù thông tin”, không biết ai truy cập và họ đã làm gì.
- Việc phản ứng trở nên bị động, chỉ phát hiện khi hệ thống ngừng hoạt động hoặc bị hacker tống tiền.
6. Phân Tích Chi Tiết Chu Trình (Áp Dụng Thực Tế)
- Triển khai công cụ giám sát như CloudWatch, Prometheus.
- Bật logging tập trung để tránh việc hacker xóa log cục bộ.
- Xây dựng sẵn các kịch bản ứng phó (playbook) cho từng loại sự cố.
- Hệ thống gửi cảnh báo khi phát hiện hành vi bất thường.
- Phân tích log để xác định nguồn tấn công và phạm vi ảnh hưởng.
- Đánh giá mức độ nghiêm trọng của sự cố.
- Ngăn chặn: Chặn IP, khóa tài khoản nghi ngờ.
- Loại bỏ: Vá lỗ hổng, xóa mã độc hoặc backdoor.
- Phục hồi: Khôi phục dữ liệu từ bản sao lưu an toàn và đưa hệ thống hoạt động trở lại.
- Thực hiện Root Cause Analysis để xác định nguyên nhân gốc rễ.
- Rút kinh nghiệm và cải thiện hệ thống giám sát, WAF, access control.
- Cập nhật lại tài liệu và quy trình ứng phó cho tương lai.